
Introducción a las buenas prácticas
Los modelos de aprendizaje automático (ML) ganan popularidad en diversas aplicaciones en ciencia de materiales. Dentro de este campo, los modelos ML se clasifican en predictivos y generativos. Los predictivos pueden predecir propiedades o características de materiales no vistos a partir de suficientes datos de entrenamiento. Los generativos van más allá. Con la información preliminar, pueden diseñar nuevos materiales con propiedades predefinidas por el usuario. El éxito de los modelos ML depende críticamente de la calidad de los datos de entrenamiento. En esta publicación, discutiremos buenas prácticas para construir conjuntos de datos de entrenamiento para modelos ML.
Buenas prácticas
Recopila datos de alta calidad
Los datos de alta calidad deben representar con precisión el problema que intentas resolver. Deben estar etiquetados de manera constante y precisa. En muchos casos, esto significa recopilar datos de bases de datos confiables y diversas. Los datos del material también deben ser representativos del espacio químico que intentas modelar. Deben cubrir un rango significativo de composiciones, simetrías o aplicaciones.
Asegura un conjunto de datos equilibrado y diverso
Además de recopilar datos de alta calidad, es importante garantizar que los datos estén equilibrados y sean diversos. Por ejemplo, en algunas aplicaciones de ciencia de materiales, los datos pueden clasificarse en diferentes clases o etiquetas, como el grupo espacial. Es importante garantizar que los datos estén equilibrados en términos de la cantidad de ejemplos en cada clase. Si una clase está sobre-representada en los datos de entrenamiento, el modelo puede sesgarse hacia esa clase. Esto puede provocar un rendimiento deficiente en datos nuevos y no vistos. Por ejemplo, un modelo generativo basado en estructuras entrenado con un fuerte sesgo hacia grupos espaciales altos, no podrá diseñar estructuras con grupos espaciales bajos de manera precisa.
Evita el overfitting
El sobreajuste (overfitting) puede ocurrir cuando un modelo se especializa demasiado en los datos de entrenamiento. En esta situación el modelo rinde mal en datos no vistos. Para evitar el sobreajuste, es importante asegurar que los datos de entrenamiento sean lo suficientemente amplios y diversos para capturar toda la gama de variación en el espacio químico. En este sentido, los ingenieros pueden calcular diferentes métricas para evaluar la diversidad química y el equilibrio del conjunto de datos. Algunos ejemplos son el número de materiales por elemento químico presente en el conjunto de datos o el número de átomos por material. Se recomienda que estas propiedades sigan una distribución homogénea dentro del conjunto de datos para evitar el sobreajuste.
Utiliza técnicas de aumento de datos
El aumento de datos es el proceso de incrementar artificialmente el tamaño del conjunto de datos de entrenamiento creando nuevos ejemplos sintéticos a partir de los datos existentes. Esto se puede hacer rotando, volteando o escalando estructuras conocidas. El aumento de datos puede ayudar a mejorar la robustez y la generalización del modelo. Puede ser especialmente útil cuando la cantidad de datos de entrenamiento es limitada.
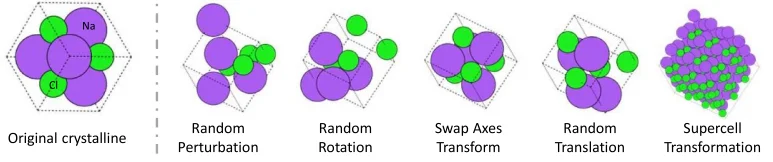
Técnicas de aumento de datos propuestas por (Magar et al., 2022).
Evalúa y mejora de forma continua
Una vez construido el conjunto de datos de entrenamiento, es importante evaluarlo y mejorarlo continuamente. Esto puede implicar el uso de datos de validación para evaluar el rendimiento de los modelos ML durante y después del entrenamiento. Utilizar esta retroalimentación para refinar y mejorar el conjunto de datos de entrenamiento con el tiempo. También puede implicar agregar nuevos datos a medida que estén disponibles o utilizar técnicas de aumento de datos para crear ejemplos adicionales.
Utiliza buenas prácticas en tus flujos de trabajo de ML
En conclusión, construir un conjunto de datos de entrenamiento de alta calidad es un paso crítico en el proceso de ML. Siguiendo estas mejores prácticas, los ingenieros pueden lograr un conjunto de datos de entrenamiento que sea robusto, representativo y efectivo para entrenar modelos ML de acuerdo con la aplicación de su elección. La calidad de los datos utilizados impactará irrevocablemente la calidad del modelo ML, por lo que es esencial dedicar suficiente tiempo para recopilar, limpiar y etiquetar los datos preliminares de manera cuidadosa. Y usar las mejores prácticas para asegurar que los conjuntos de datos de entrenamiento sean equilibrados, diversos y poderosos.
