
Introduction to best practices
Machine learning (ML) models are becoming increasingly popular for a wide range of applications in materials science. Within this field, ML models are often classified as predictive and generative. Predictive models can predict certain properties or characteristics of unseen materials from a sufficient amount of material-property training data. Generative models go a step further and are able to take this preliminary information to design new materials with user predefined properties. The success of ML models depends critically on the quality of the training data that is used to teach them. In this post, we will discuss some best practices for building training datasets for ML models.
Best practices
Gather high-quality data
High-quality data must accurately represent the problem you are trying to solve and must be labeled consistently and precisely. In many cases, this means gathering data from trusted and diverse databases. The material data should also be representative of the chemical space you are trying to model, and should cover a significant range of compositions, symmetries or applications.
Ensure balanced and diverse data
In addition to gathering high-quality data, it is important to ensure that the data is balanced and diverse. For instance, in some material science applications, the data might be classified into different classes or labels, such as spacegroup. It is important to ensure that the data is balanced in terms of the number of examples in each class. If one class is over-represented in the training data, the model may become biased towards that class. This might cause a poor performance on new, unseen data. For example, consider the case of a structure-based generative model is trained with a strong bias towards high space groups. This model will not be able to accurately design structures with low space groups.
Avoid overfitting
Overfitting might occur when a model becomes too specialized to the training data and performs poorly on unseen data. To avoid overfitting, it is important to ensure that the training data is large enough and diverse enough to capture the full range of variation in the chemical space. In this regard, engineers can calculate different metrics to evaluate the chemical diversity and balance of the dataset. Some examples are the number of materials per chemical element present in the dataset or the number of atoms per material. It is often recommended that these properties follow a homogeneous distribution within the dataset to avoid overfitting.
Use data augmentation techniques
Data augmentation is the process of artificially increasing the size of the training dataset by creating new synthetic examples from existing data. This can be done by rotating, flipping, or scaling known structures. Data augmentation can help to improve the robustness and generalization of the model. It can be especially useful when the amount of training data is limited.
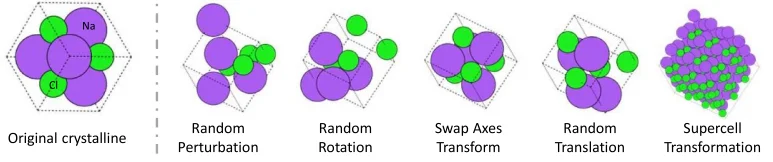
Data augmentation techniques proposed by (Magar et al., 2022).
Continuously evaluate and improve
Once training dataset is built, it is important to continuously evaluate and improve it. This may involve using validation data to assess the performance of the ML models during and after training, and using this feedback to refine and improve the training dataset over time. It may also involve adding new data as it becomes available, or using data augmentation techniques to create additional examples.
Use best practices in your ML workflows!
In conclusion, building a high-quality training dataset is a critical step in the ML process. By following these best practices, engineers can achieve a training dataset which is robust, representative, and effective for training ML models according to the application of their choice. The quality of the used data will irrevocably impact the quality of the ML model, so it is essential to take enough time to gather, clean, and label the preliminary data carefully, and use best practices to ensure that training datasets are balanced, diverse, and powerful.
